
Prompt engineering is all about designing inputs—prompts—that steer AI models toward generating accurate, useful outputs. Multimodal prompt engineering takes this concept up a notch by creating prompts for AI systems that handle multiple data types simultaneously: think text paired with images, audio or even video.
In the ever-evolving world of artificial intelligence, prompt engineering has emerged as a cornerstone skill for anyone. What started as a way to craft text inputs for large language models (LLMs) like GPT-4 has now expanded into something far more exciting: multimodal prompt engineering. By 2025, AI systems are no longer confined to text—they seamlessly process images, audio, video and more. This shift is transforming industries and opening new possibilities for innovation.
The Need to Adapt to a Multimodal Future
AI is now deeply embedded in our lives, powering everything from medical diagnostics to financial fraud detection. Traditional text-only prompts can’t keep up with the complexity of these tasks. Multimodal systems, on the other hand, can integrate with diverse data sources to handle complex scenarios, proven by result-driven real-world applications. Whether it’s analyzing an X-ray alongside a patient’s medical history or spotting fraud by combining transaction logs with user behavior visuals, multimodal prompt engineering is unlocking AI’s full potential.
The catch? It’s trickier than text-based prompts. Each data type has its own quirks and getting them to work together requires advanced strategies. Let’s dive into two of the most powerful techniques shaping this space.
Exploration of 2 Advanced Techniques
1. Greedy Prompt Engineering Strategy (Greedy PES)
The Greedy Prompt Engineering Strategy (Greedy PES) is a game-changer for optimizing prompts across datasets and multimodal large language models (MLLMs). It’s a hybrid approach that pulls together several proven methods:
- In-Context Learning (ICL): Embedding examples in the prompt to guide the model.
- Chain of Thought (CoT): Encouraging step-by-step reasoning.
- Step-by-Step Reasoning (SSR): Breaking down problems into bite-sized pieces.
- Tree of Thought (ToT): Exploring multiple reasoning paths.
- Retrieval-Augmented Generation (RAG): Pulling in external knowledge for richer responses.
At a technical level, the Greedy Prompt Engineering Strategy (Greedy PES) runs an exhaustive, score-driven search across different prompt techniques and multimodal large language models (MLLMs) to get the most accurate and reliable results for a given dataset.
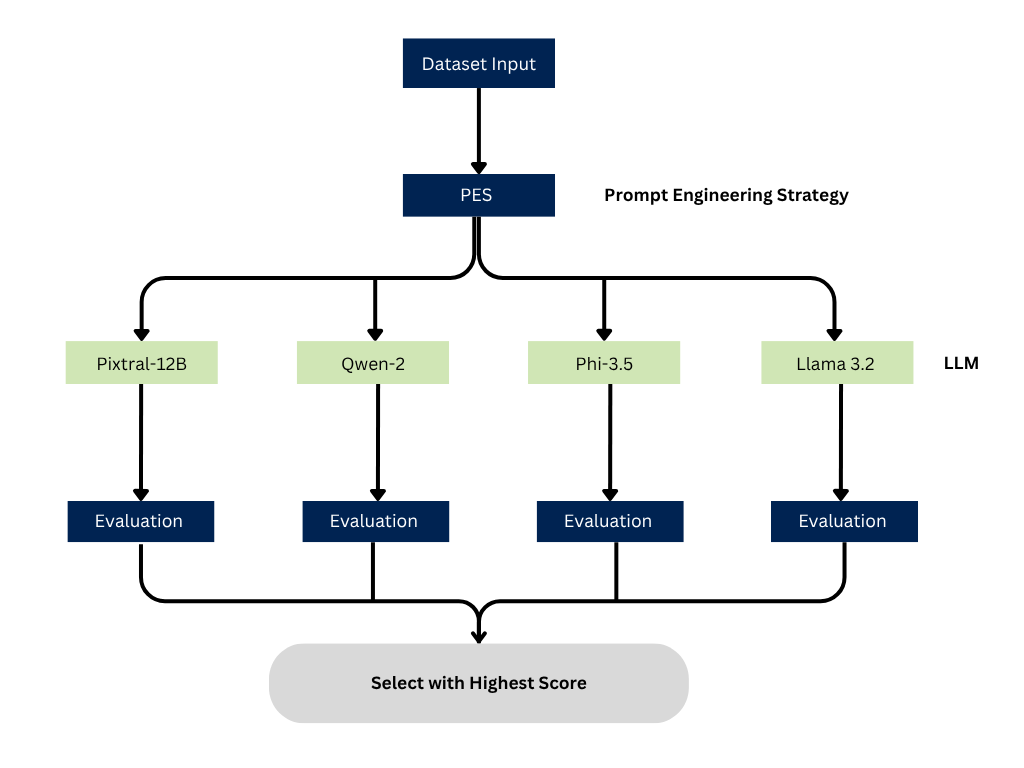
A dataset, whether it’s single or multi-format (like text paired with images) is first loaded in, and various prompt engineering strategies such as Chain-of-Thought (CoT), Self-Consistency, and RAG are systematically applied.
Each strategy is tested with multiple MLLMs (e.g., Llama-3.2-11B, Phi-3.5-4.2B, Pixtral-12B, and Qwen2-VL-7B), covering all possible model-strategy pairs. These combinations are run across the dataset, and the outputs are scored using a wide set of evaluation metrics like BLEU, ROUGE, METEOR, S-BERT, MoverScore, and CIDEr — many of which are adapted to handle multimodal tasks.
The combination that gets the highest overall score is chosen as the best forming a greedy, straight-line path to the best prompt-model setup without looking back.
Greedy PES is especially useful in multimodal use cases, where things get more complex due to how the different input types interact. By separating strategy from model and testing every possible combo, it helps surface powerful pairings that aren’t easy to discover manually.
The result is a well-tuned prompt-model setup that fits the input data format — ready for downstream tasks, fine-tuning, or even model distillation.
What sets Greedy PES apart is its knack for reducing hallucination—those critical moments when AI generates responses that may look accurate but are factually incorrect. By tailoring prompts for specific datasets and models, it ensures more reliable outputs, especially in high-stakes fields like healthcare.
2. Multimodal Chain-of-Thought (CoT) Prompting
If you’ve used Chain-of-Thought (CoT) prompting for text-based tasks, you know it’s great for getting models to reason logically. Multimodal CoT takes this further by weaving together text and visual inputs in a two-stage process:
- Rationale Generation: The model builds a reasoning path based on both data types.
- Answer Inference: It uses that rationale to deliver the final answer.
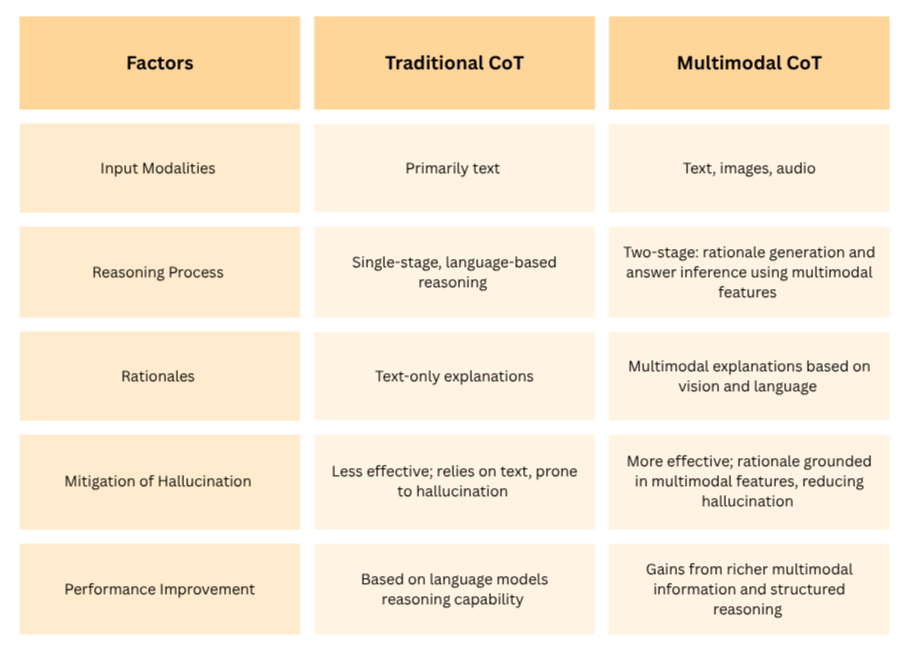
This enables the model to think through problems that involve multiple data types — for example, answering a question about a chart or interpreting an image alongside a caption.
What makes Multimodal CoT so powerful is its ability to break down complex tasks into manageable reasoning steps, grounded in more than just text. It doesn’t just look at an image and guess — it processes what it sees, connects it with textual information, and builds a structured explanation before reaching a conclusion.
By integrating visual context directly into the thought process, it improves the model’s interpretability and reduces the chance of hallucinated or unsupported answers redefining areas where accuracy and traceability matter like scientific analysis & data interpretation.
Real-World Applications: Industry Impact
Multimodal prompt engineering is no longer confined to research labs. It’s actively reshaping workflows across healthcare, finance, and creative production, offering new design patterns for building AI systems that reason across modalities.
1. Healthcare
In healthcare, clinical systems are now pairing structured text (e.g. symptoms, history) with diagnostic imagery (CT, MRI, ultrasound) to enable models that don’t just classify but correlate.
Prompt engineering here involves breaking down tasks into steps across modalities like reading lab reports, then comparing them with symptom progression and finally an image scan (such as X-ray) forming a full diagnosis workflow. These advances are now raising the standard and accuracy for next-generation tools used in diagnosis and radiology support.
2. Finance
Teams are starting to build fraud detection systems that combine user behavior data—like click patterns or session flows—with traditional transaction records. By designing prompts that help the model connect the dots between these two types of input, it’s possible to catch suspicious activity more accurately. For AI teams, this means learning how to write prompts that handle both structured financial logs and messier user behavior data in a single flow.
3. Creative Industries
AI systems are now trained to align visual composition, audio pacing, and narrative context helping automate editing, tagging, summarization, and asset selection. What previously required human composition between media types can now be modeled as prompt-led workflows across formats, enabling faster and more consistent output.
The thread across all of these: multimodal prompts aren’t just about handling different data types, they structure reasoning itself across them. This shift is redefining how AI interfaces are designed, how tasks are decomposed, and how models are steered in real world environments.
Google I/O 2025: What’s New in Multimodal Intelligence
Building on the core practices of multimodal prompt engineering, Google’s announcements at I/O 2025 offer concrete examples of how next-generation AI tools leverage and indeed require refined prompt strategies across text, image, audio and video modalities.
- Gemini 2.5 Pro & Deep Think: Enabling Advanced Multimodal Reasoning
Gemini 2.5 Pro’s new Deep Think mode is tailored for complex, multimodal tasks—such as diagnosing medical images paired with patient histories or interpreting annotated architectural plans. Prompt engineers can define multi-stage chains of thought across modalities: for instance, “Extract features from this X-ray image; (2) Correlate with the accompanying lab results; (3) Formulate a differential diagnosis.” Deep Think’s architecture rewards explicit, ordered pipelines, reinforcing the importance of well-structured CoT prompts in achieving high-accuracy, domain-specific AI assistance. - Flow & Veo 3: Video Generation via Iterative Prompt Refinement
Google’s new Flow app, powered by Veo 3 and Veo 2, lets users generate and put together short, AI-driven video clips using text or image prompts. You start with a concise base prompt—e.g., “Generate a sunrise over mountains with gentle orchestral music”—then inspect the draft clip and add new instructions (camera angle, lighting settings, soundtrack choices). This iterative process not only uses a best-step approach (like greedy PES) it also allows the users to identify the one change that gives the biggest improvement demonstrating why multimodal prompt engineering is essential to synchronize visual, audio and stylistic elements independently into one instruction set. Over successive passes, you settle in on a finely tuned, multimodal prompt that reliably produces your desired video output. - Prompt API with Multimodal Capabilities: Structuring Prompts for Complex Inputs
The new Chrome Prompt API (now supporting images and voice alongside text) exemplifies how developers can embed multimodal data directly into their prompts—whether building a browser extension that analyzes a webpage screenshot plus a user’s annotation, or a chatbot that interprets voice clips plus typed queries. Applying best practices from multimodal CoT, engineers structure these prompts in stages (e.g., “First, identify key UI elements in this screenshot; second, summarize their function; third, suggest improvements”) to guide the model through a clear, step-by-step reasoning path. - Google Beam & Project Astra: Real-Time, Context-Aware AI Interactions
With Google Beam’s live, camera-and-voice–enabled assistant and the low-latency Project Astra platform for AR glasses, prompt engineering extends into continuous, interactive flows. Here, effective prompts blend preamble (“You are an assistant that identifies mechanical parts”) with real-time context (“Now describe the component highlighted in the live video feed”). This dynamic fusion of static prompt design and on-the-fly multimodal inputs underscores the next frontier of prompt engineering: crafting systems that adapt in real time to evolving user data. - Gemini Text-to-Speech: Structured Audio Synthesis
With the newly released Gemini 2.5 TTS models, speech synthesis has transcended with single-speaker and multi-speaker text-to-speech which can be engineered with natural language to set the tone, volume, accent, pace and style of the audio. Developers can craft prompts like “Generate a dialogue where person A speaks with clarity and calmly in English whereas person B responds excitedly in Mandarin, next both whisper a shared secret”. Then iterate to adjust tone, accent or pace which helps to sync audio with visuals in tools such as Veo 3 and is accessible via Gemini API. This empowers developers to build immersive experiences from video voiceovers to real-time assistants, proving that prompts are key to unlocking audio’s role in multimodal intelligence.
Why This Matters in 2025?
By 2025, AI-driven interfaces will manage the majority of customer interactions, with multimodal systems at the forefront of that shift. Understanding this landscape reveals three key insights:
- Emergence of Specialized Roles: As multimodal prompt engineering techniques such as Greedy PES and multimodal Chain-of-Thought become core to system performance, the need to understand and further explore these pipelines even further has risen.
- System Reliability Through Prompt Design: Mastery of prompt-level control over text, image, audio and video inputs directly correlates with the stability and predictability of AI outputs, reducing downstream error rates and support overhead.
- Frontier AI Capabilities: With robust multimodal prompts, systems can tackle increasingly complex tasks like automated diagnostics, contextual content creation, real-time translation opening up avenues for applications that are still theoretical today.
Prompting is no longer a niche discipline; it’s a must have fundamental skill. As we enter the age of multimodal intelligence, let’s take the lead in building AI systems that can see, listen, speak and think across every mode of input.
